汇编基础和函数调用ABI
内容:简单总结 x86 汇编基础和函数调用的过程,但只涉及可用指令和汇编指令的一小部分,但非常有用。主要采用 GNU 汇编器(GAS) 的 AT&T 语法进行说明。
补充的资料:
- x86 and amd64 instruction reference
- CMPT 295 Lecture Notes
- CS107 Computer Organization & Systems CSAPP
- CMU 15-213/15-513 Introduction to Computer Systems CSAPP
- Compiler Explorer - godbolt.org
1.寄存器
x86 寄存器
x86 处理器有 8 个通用寄存器,如下图,其中 EAX 过去被称为累加器,因为它被许多算术运算使用;ECX 被称为计数器,因为它被用来保存循环索引,然而现在基本上失去了其专有目的,成为通用寄存器。但是 EBP 通常用于栈基指针,ESP 用于栈顶指针。
- x86 处理器,通用寄存器是 32 位的,寄存器
EAX、EBX、ECX、EDX还可以分别访问其低地址的 16 位,和其中的高低字节。如下图中所示。 - 汇编语言中,寄存器名称是不区分大小写的。
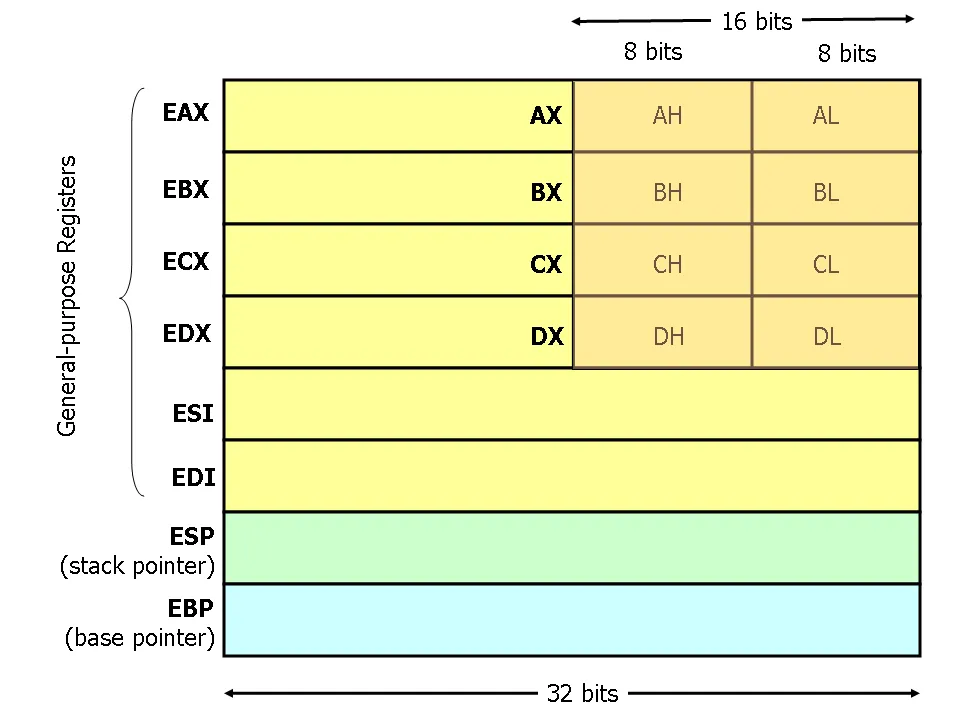
- 32 位系统中,调用者需要保存的寄存器 caller-saved 有
EAX、ECX、EDX,被调用者 callee-saved 需要保存的寄存器有EBP、EBX、EDI、ESI。
x86-64 寄存器
x86-64 处理器扩展了上述通用寄存器到 64 位,并增加了一些新的寄存器,如 R8~R15,所以有 16 个 64 位寄存器。但是,为了向后兼容,32 位寄存器仍然可以使用。
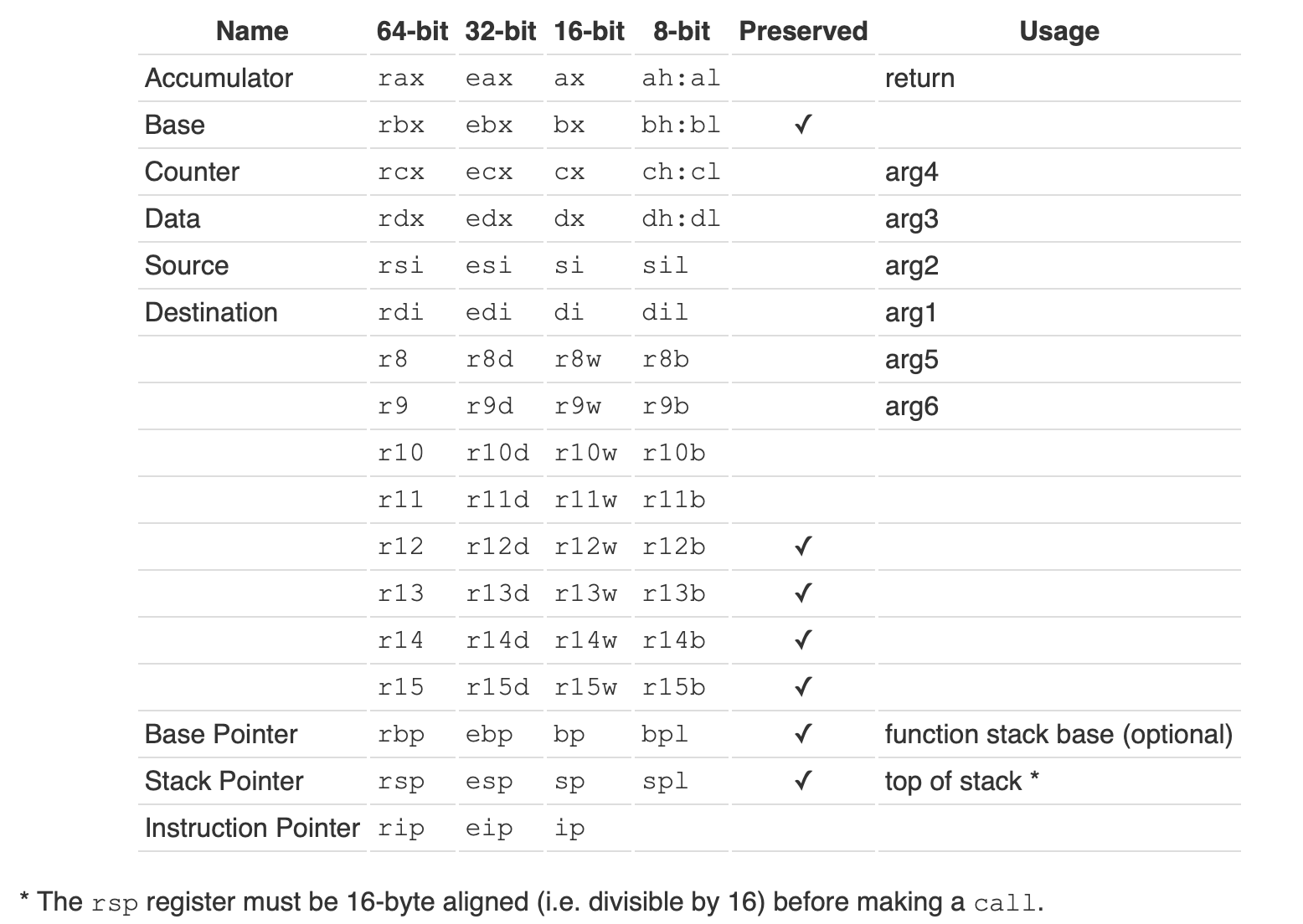
- 所有的 64 位寄存器使用
R前缀访问,如RAX、RBX、RCX、RDX如上图。 - 如图,寄存器 %rbp, %rbx, 和 %r12-%r15 是被调用者 callee 需要保存的(换句话说,它们属于调用者 caller,调用者假定它们的值不会被修改)。当然,是按照实际使用情况进行保存,如果被调用者使用了这些寄存器,那么需要在函数序幕保存这些寄存器的值,然后在函数结束时恢复这些寄存器的值。
剩余的寄存器,调用者负责保存。
SIMD: MMX, SSE, AVX, AVX-512
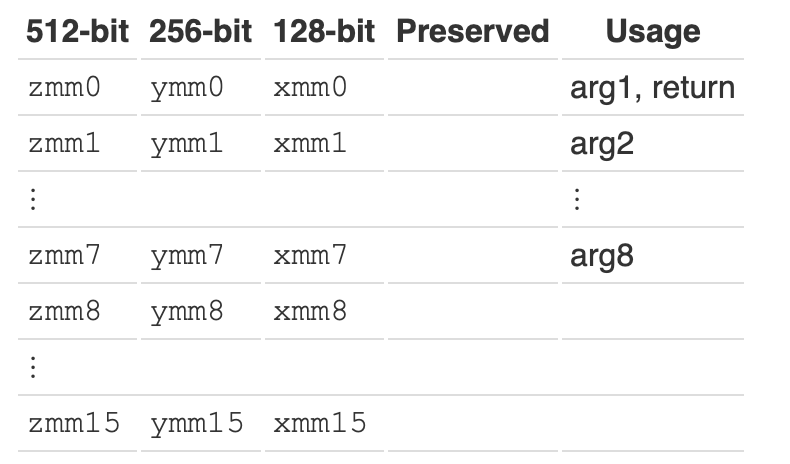
此外,还提供了 16 个 SSE 寄存器(xmm0~xmm15),每个寄存器宽度 128 位,以及 8 个 x87 指令浮点寄存器(st(0)~st(7)),每个寄存器宽度 80 位(主要用于早期的浮点计算, 以及 MMX 指令会共享该寄存器)。
Intel AVX(高级向量扩展)提供了 16 个 256 位的 YMM 寄存器(ymm0~ymm15),其低 128 位即对应的 128 位 SSE 寄存器(别名);AVX-512 扩展提供了 32 个 512 位的 ZMM 寄存器(zmm0~zmm31),其低 256 位对应于 256 位 YMM 寄存器,低 128 位对于 128 位 XMM 寄存器。(因此 xmm16 - %xmm31 / ymm16 - ymm31 只在 AVX-512 扩展中有效)
我们将使用这些寄存器和 SIMD 指令进行浮点运算:
2.汇编语法
https://sourceware.org/binutils/docs/as/index.html
GNU 汇编快速入门
这里主要使用 AT&T 语法,它是 GNU 汇编器(GAS) 的默认语法。AT&T 语法的特点是源操作数在前,目的操作数在后,操作数之间用逗号分隔。如下所示:
pushq %rbp
movq %rsp, %rbp
movl %edi, -20(%rbp)
movl %esi, -24(%rbp)
movl %edx, -28(%rbp)
movl -20(%rbp), %eax
movl %eax, -4(%rbp)
......
popq %rbp
ret
与 Intel 汇编语法的主要区别有:全面的差异
| 差异 | AT&T 语法 | 说明 | Intel 语法 | 说明 |
|---|---|---|---|---|
| 操作数顺序 | movq %rsp, %rbp |
源操作数在前,目的操作数在后 | mov rbp, rsp |
目的操作数在前,源操作数在后 |
| 指令后缀 | movq %rsp, %rbp |
指令后缀表示操作数大小,如 q 表示四字操作 |
mov rbp, rsp |
不用后缀,通过寄存器操作数推断大小;内存寻址大小歧义时用 BYTE PTR 等显示标注 |
| 寄存器 | %rsp |
寄存器名称前加 % |
rsp |
寄存器名称不加 % |
| 操作数中的立即数 | movq $0x2, %rax |
操作数中的立即数前加 $ |
mov rax, 0x2 |
不加 $ |
| 内存引用 | movq 8(%rsp), %rax |
立即数在 () 外面 |
mov rax, [rsp+8] |
立即数在 [] 里面 |
| 跳转/call 操作数 | je *%rax, callq *%rax |
操作数前加 * |
je rax, call rax |
不加 * |
| 注释 | # comment |
注释符号为 # |
; comment |
注释符号为 ; |
指令后缀
多数指令使用后缀来表示操作数的大小,如:
b:byte 表示字节操作,如movb、addb。w:word(2 bytes) 表示字操作,如movw、addw。l:long/doubleword(4 bytes) 表示双字操作,如movl、addl。q:quadword(8 bytes) 表示四字操作,如movq、addq。
如果可以从操作数中推断出操作数的大小,可省略后缀。如 movq %rsp, %rbp 可以写成 mov %rsp, %rbp,操作数 %rsp 暗示 q,%eax 暗示 l,以此类推。
少数指令例如 movs(符号扩展)、movz(零填充)有两个后缀,第一个表示源操作数位宽,第二个表示目的操作数位宽,例如 movzbl 移动一个字节长度源操作数到一个双字长度目的操作数,高位用 0 填充。
Note: 当目标寄存器是子寄存器时,只有子寄存器范围的字节会被写入更新,但有一个例外:32 位的指令写入时,会将目标寄存器的高 32 位清零,例如 mov $ebx, %ebx 这种看似冗余的指令会进行将 rbx 的高 32 位清零。这里等效 movzlq %ebx, %rbx。
内存寻址(访问)
指令中访问内存的一般形式是:
displacement:立即数,表示偏移量。base:基址寄存器,表示基址。index:索引寄存器,表示索引。scale:比例因子,表示索引寄存器的倍数。
例如,。
以写立即数 1 为例说明多种寻址模式:
movl $1, 0x604892 # 直接寻址,地址 0x604892
movl $1, (%rax) # 间接寻址,地址为 rax 寄存器的值
movl $1, -24(%rbp) # 基址+偏移,地址为 rbp 寄存器的值减去 24
movl $1, 8(%rsp, %rdi, 4) # 基址+索引*比例+偏移,地址为 rsp + rdi * 4 + 8
movl $1, 0x8(, $rdx, 4) # 索引*比例+偏移,地址为 rdx * 4 + 8
movl $1, 0x4(%rax, %rcx) # 比例假定为1,地址为 rax + rcx + 4
常用指令
常用的指令和寻址方式可以参考:Common instructions and Addressing modes - cheatsheet
主要有数据移动、算术运算/逻辑运算、控制流等。
数据移动
mov:数据传送指令,如movl %eax, %ebx。movz: 0 填充(小位宽赋值到大位宽),如movzbl (%rdi), %eax, 其中后缀b表示字节操作,l表示双字(双指令后缀)。movs: 符号扩展(小位宽赋值到大位宽),如movsbl (%rdi), %eax, 其中后缀b表示字节操作,l表示双字。cltq: movs 指令对rax寄存器特化指令,将其低 32 位符号扩展到 64 位。push:将数据压入栈,如pushq %rbp。具体操作:栈顶指针减去 8,然后将数据写入栈顶。pop:将数据弹出栈,如popq %rbp。具体操作:读取栈顶数据,然后栈顶指针加 8。lea: 取操作数的有效地址,不进行地址解引用,如lea 8(%rsp), %rax。
算术运算/逻辑运算
许多算术指令同时适用于有符号和无符号类型。例如 add、sub 等。通过操作后设置的标志位可以检测不同类型的溢出。
add:加法,如addl %eax, %ebx。sub:减法,如subl %eax, %ebx。inc/dec: 自增/自减,如incl %eax。neg:取负数,如negl %eax。imul:整型有符号乘法,如imull %eax, %ebx。结果保存在[EDX:EAX]中,高 32 位在EDX中,低 32 位在EAX中。idiv:整型有符号除法,如idivl %eax。使用idiv之前,需要将被除数放在EDX:EAX中。结果的商保存在EAX中,余数保存在EDX中。mulss/divss: 标量单精度浮点数乘法/除法 scalar single-precision,如mulss %xmm1, %xmm2。mulsd/divsd: 标量多精度浮点数乘法/除法 scalar double-precision,如mulsd %xmm1, %xmm2。and/or/xor:按位与/或/异或,如andl %eax, %ebx。not:按位取反,如notl %eax。shl/shr:逻辑左移/右移,省略源操作数则默认为 1,如shll $2, %eax。sal/sar:算术左移/右移,省略源操作数则默认为 1,如sarl $2, %eax。
控制流指令
eflags 标志寄存器用于存储条件码,条件码是由上一条指令设置的,并且大多数算数指令会更新这些标志。条件码用于控制条件跳转指令。常用的标志位有:ZF(零标志位)、SF(符号标志位)、OF(溢出标志位)、CF(进位标志位)。

OF:溢出标志位,针对有符号数,当结果超出有符号数的表示范围时设置。包括正溢出和负溢出。CF:进位/借位标志位,针对无符号数,当结果超出无符号数的表示范围时设置。包括无符号加法进位和无符号减法借位。
条件跳转指令和使用的标志位对应如下:
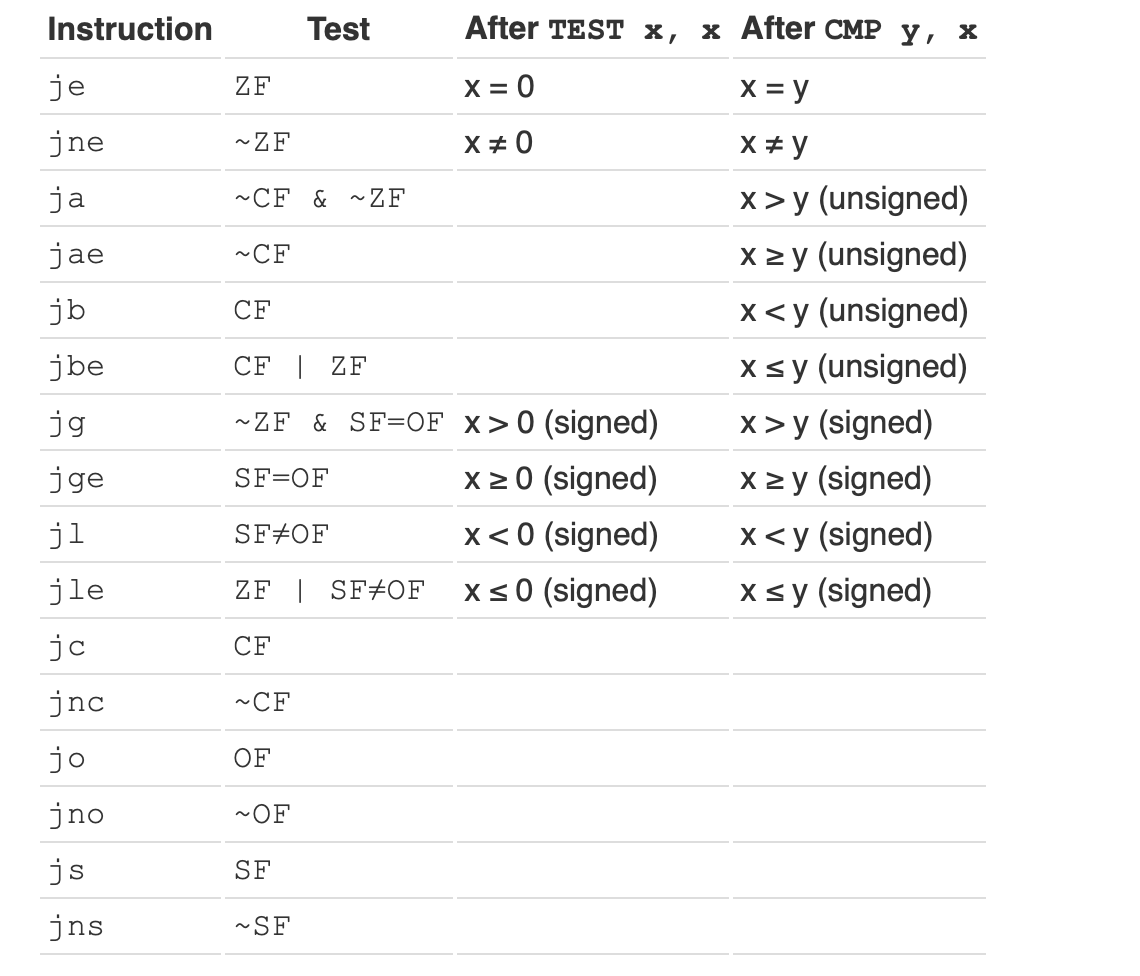
- TEST 指令:与
AND指令类似,但是不保存结果,只设置标志寄存器,如testl %eax, %eax。 - CMP 指令:与
SUB指令类似,但是不保存结果,只设置标志寄存器,如cmpl %eax, %ebx。与分支指令配合使用。 jmp:无条件跳转,如jmp label。- call 指令:调用函数,如
call func, 其操作是:将下一条指令的地址压入栈,然后跳转到函数的入口地址。 - ret 指令:返回,如
ret。其操作是:将弹出的返回地址加载到指令指针寄存器(RIP)中,从而跳转到函数调用后的下一条指令,继续执行。 - leave 指令:恢复栈帧,如
leave。其操作是:将栈帧指针rbp的值赋给栈顶指针rsp(清空当前栈帧),然后弹出栈帧指针rbp(恢复原始 rbp, 还原上一个栈帧)。
和标志寄存器相关的指令:有两种常见指令可以读取/响应当前标志寄存器的值
setx:x是条件占位符,根据条件(x)设置一个字节寄存器为 0 或 1,如sete %al。cmovx:条件移动指令,x是条件占位符,根据条件(x)将源寄存器复制到目的寄存器,如cmovle %eax, %ebx。
上面命令中的x是条件占位符,值及其含义与上图中的条件跳转指令相同。
3.函数调用
为了允许共享代码并简化子程序的使用,程序员通常采用一种通用的调用约定。调用约定是一种关于如何调用和返回例程的协议。例如,给定一组调用约定规则,程序员不需要检查子程序的定义来确定如何将参数传递给该子程序。此外,给定一组调用约定规则,高级语言编译器可以按照这些规则进行编译,从而允许手动编写的汇编语言例程和高级语言例程相互调用。
MacOSX 和 Linux 的 x86-64 调用协议都遵循 SystemV ABI (见参考资料)。
函数参数
ABI 将参数/返回值定义了多种类别,依据寄存器的种类定义为:INTEGER(整型,能够适应于通用寄存器 8B)、SSE(能够适应于单个向量寄存器 8B)、SSEUP(继续利用上次使用的向量寄存器中的高字节部分>8B)、MEMORY(通过栈传递的类型)和其他类型。
函数调用的前 6 个(整型,包括指针)参数通过寄存器传递,传递顺序为 %rdi,%rsi,%rdx,%rcx,%r8,%r9(如图所示 arg1~arg6)。超出部分的参数通过函数栈帧传递。
如果函数有返回值(整型),%rax 用作第一个函数返回值,%rdx 用作第二个函数返回值。浮点数使用 xmm0 作为返回值。
其他一些规则:
- 如果参数大于 64 字节对象,对应于 MEMORY 类型,通过栈传递。
- 注意如果返回值是 MEMORY 类型,调用者会自己为返回值分配空间,并使用
%rdi隐式传递该内存指针作为第一个参数。被调用函数对该内存赋值后,直接返回该指针。
函数栈帧
每个函数在运行时堆栈上都有一个帧。函数栈帧从高地址往低地址方向增长,System V ABI 使用两个寄存器访问函数栈帧:帧指针 %rbp 和栈指针 %rsp。 帧指针 %rbp 指向当前函数栈帧基址(栈底),栈指针 %rsp 指向当前函数栈帧栈顶。
函数调用的栈帧结构图如下所示:
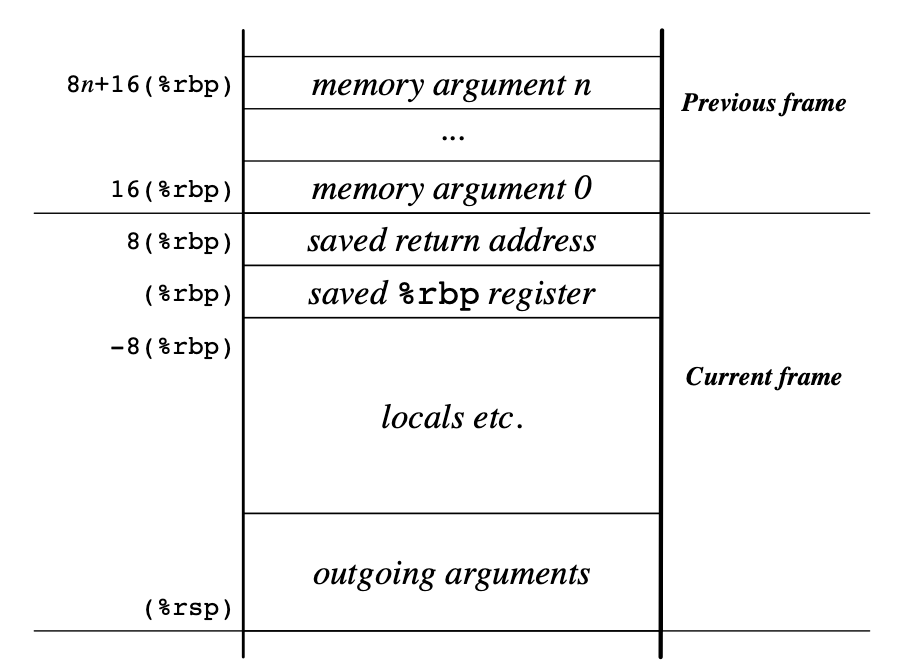
- 帧指针
%rbp用来存取函数栈帧上的数据,例如传递进来的函数参数,或者函数的本地局部变量。 System V ABI 要求最后一个压入栈的函数参数(argument 0)地址需要 16 字节边界对齐,如果有__m256类型的参数使用栈传递,则需要 32 字节边界对齐。 - 可以看出,通过栈传递的其他参数,第一个参数的位置在
%rbp+16, 中间隔着 8 字节的返回地址。在 32 位系统中,第一个参数的位置在%ebp+8。(只是 32 位系统在参数传递和寄存器保存上有所不同)
栈红区(red zone)优化:红区是栈上 rsp 指向位置之后的 128 字节区域。该区域在函数调用时被认为是保留的,期间不被信号处理程序和中断处理程序修改,从而保护了函数栈的完整性。所以函数可以安全地使用这个区域来存储临时数据。
可用于优化函数调用:叶函数(即不调用其他函数的函数)可以利用红区作为整个栈帧的一部分,而不必在函数入口/序言和退出/结尾时调整栈指针(直接使用 rsp 寻址,并且不显示地调用 subq $N, %rsp 分配空间,直接使用栈红区作为整个栈帧)。这可以减少栈操作的开销,提高函数调用的性能。
函数调用协议
函数调用协议分为 caller 端和 callee 端,每端各有两个重要步骤:
1)caller 调用者:
- 【保存 caller-save 寄存器到函数栈上(按需保存)】;
- 将函数参数存储到规定的寄存器中,并将超出约定的参数按顺序压入栈中;(32 位系统中,通常仅用栈传递参数,参数按照从右到左的顺序依次压栈)
- 调用
call指令。(先压入返回地址,再跳转执行)
2)callee 被调用者,函数序言:
pushq %rbp压入rbp寄存器,用来保存前一个栈帧基址;movq %rsp, %rbp初始化rbp寄存器,用来指向当前栈帧基址;(新的rbp常用于寻址参数/局部变量)- 为局部变量分配空间,
subq $N, %rsp; - 【保存 callee-save 寄存器到函数栈上(按需保存)】
3) callee 被调用者,函数尾声:
函数体执行完毕后,需要执行以下步骤:
- 将函数返回值置入
rax中(浮点数置入xmm0); - 【如果保存了 callee-save 寄存器,使用
popq倒序从栈帧中恢复寄存器 】; - 释放当前函数的栈帧空间,
movq %rbp %rsp先回退栈顶指针%rsp,popq %rbp再恢复原基址指针%rbp。(两个操作,合并等效为leave指令); ret指令,弹出返回地址,执行流回到 caller 。
4)caller 调用者:
- 如果为函数参数额外分配了栈空间,则在此时需要释放这些空间。
- 【如果保存了 caller-save 寄存器,
popq倒序从栈帧中恢复,释放这些空间】;
至此,一个完整的函数调用过程完成。函数执行的结果一般位于寄存器 rax 中,如果是浮点数,位于在 xmm0 中。
说明:
- 浮点数,使用浮点寄存器
xmm0~xmm7传递参数,返回值使用xmm0~xmm1。 - 如果是对象作为返回值(对应为 MEMORY 类型时),会隐式传递其指针作为第一个参数。函数内直接修改这个指针指向的内存。
4.GDB
参考资料
MIPS
MIPS(Microprocessor without Interlocked Pipeline Stages)是一种精简指令集计算(RISC)架构,广泛应用于嵌入式系统、网络设备以及教育领域。它的设计强调简洁性和高效性,所有指令的长度固定为 32 位(部分版本支持 16 位压缩指令)。
MIPS 有32个通用寄存器:
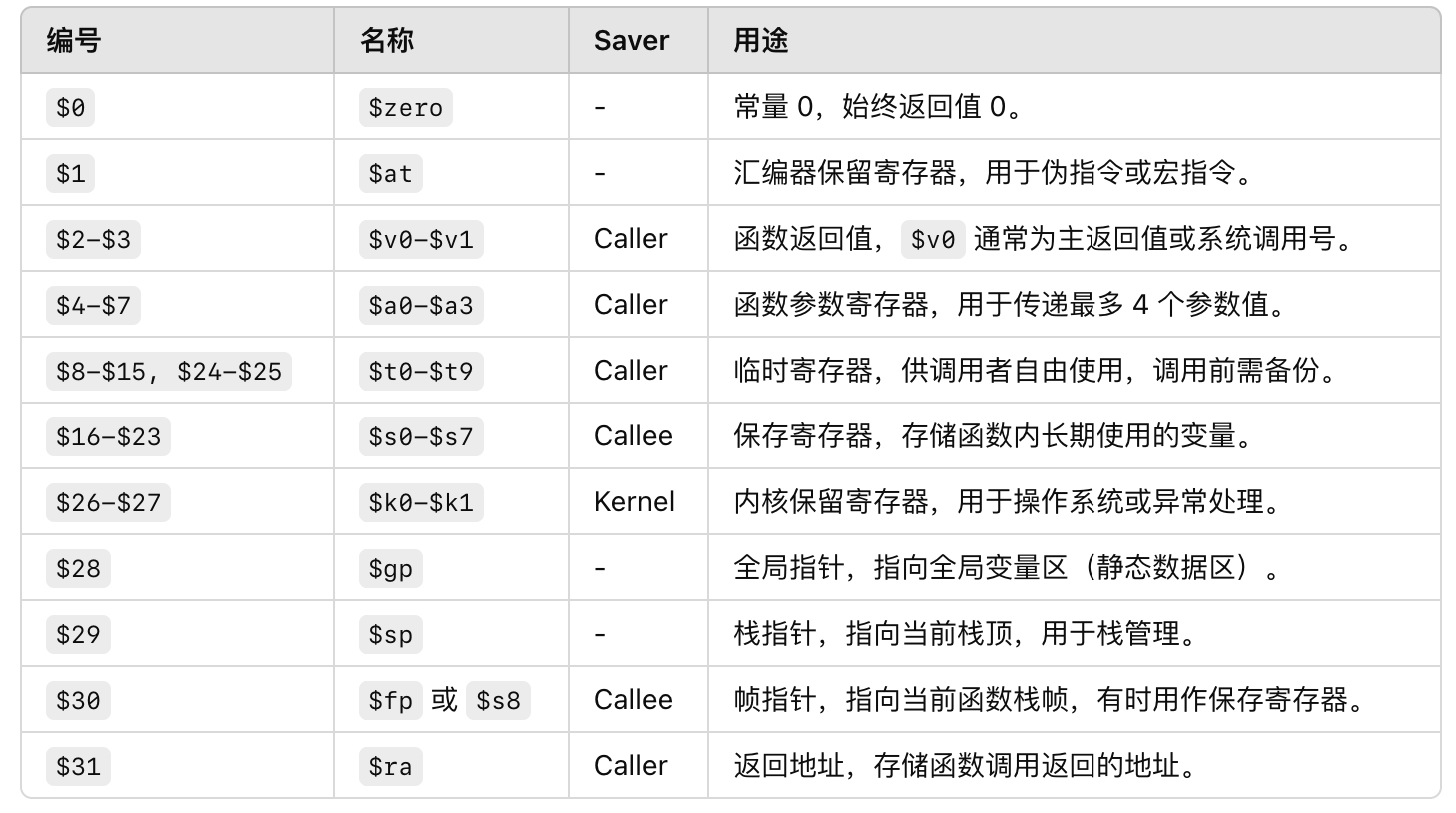
函数调用:
- 参数传递:通过
$a0-$a3(MIPS32)或$a0-$a7(MIPS64)传递前 4 或 8 个参数,更多参数通过栈传递。 - 返回值:通过
$v0和$v1返回函数结果。 - 调用者 Caller 保存寄存器:
$t0-$t9 - 被调用者 Callee 保存寄存器:
$s0-$s7
mips assembly lecture - by nju
RISCV
RISC-V 是一种基于精简指令集(RISC)的开源指令集架构(ISA),其设计具有模块化、灵活性和跨平台支持的特点。基础指令集(如 RV32I、RV64I)只提供最基本的操作,其他功能通过扩展模块实现,例如:
- M 扩展(整数乘除法):支持整数的乘法和除法操作。
- F 扩展(单精度浮点数):支持浮点运算。
- D 扩展(双精度浮点数):扩展浮点运算到双精度。
- C 扩展(压缩指令集):减少指令长度,提高代码密度。
- V 扩展(向量处理):支持高效的数据并行计算。
RV32I 有32个通用寄存器:
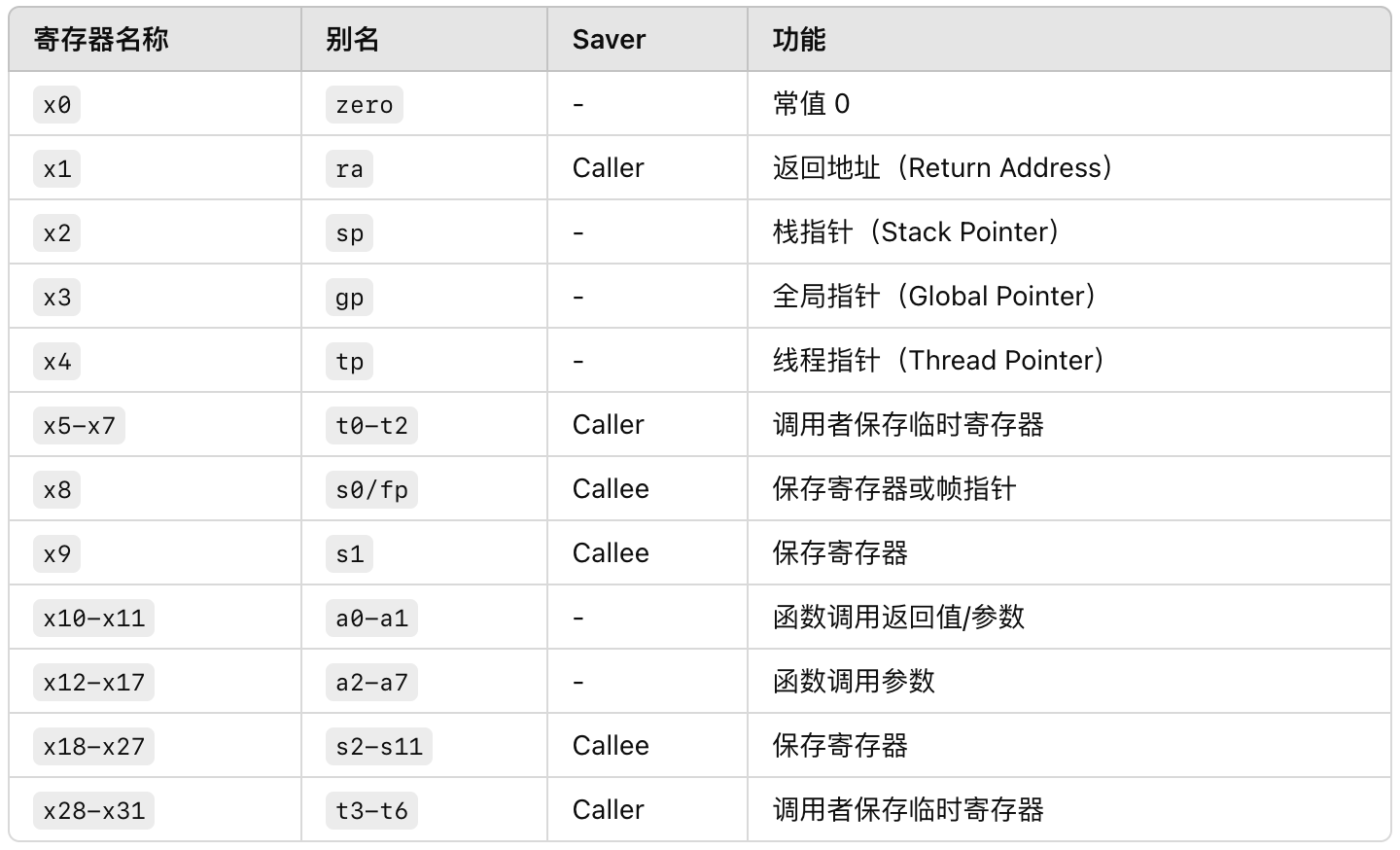
- 由调用者 Caller 负责保存和恢复,临时寄存器:
t0-t6 - 由被调用者 Callee 负责保存和恢复,保存寄存器:
s0-s11 - 参数寄存器:
a0-a7
阅读
模拟器
本文链接: 汇编基础和函数调用ABI
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
发布日期: 2024-07-23
最新构建: 2026-01-13
欢迎任何与文章内容相关并保持尊重的评论😊 !